最近闲暇时间研究一下机器学习的算法应用,随笔记录一些自己看到的精华部分和实验结果,先从最简单的邻近算法开始吧。
算法实现思想
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
使用场景
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合
重点参数
- n_neighbors:指定K值(参考K个邻居的值)
- weights:权重
- uniform:k个邻居的权重平等
- distance:距离越近权重越高
- callable:自定义举例与权重的关系
- algorithm:算法
- ball_tree
- kd_tree
- brute
- auto:交给fit函数决定算法
实验
利用datasets库生成200个样本分为3类,并取样本的X,Y的最大最小值分别±1,为测试样本的最大最小值,步长为0.02生成测试集合,具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors
from sklearn.datasets.samples_generator import make_classification
# 生成样本集合,200个样本,2个特征维度,3个分类标签
X, y = make_classification(n_samples=200, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
clf = neighbors.KNeighborsClassifier(n_neighbors=15, weights='distance')
clf.fit(X,y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = 0.02
# np.arange(start,end,step)生成一个数组
# np.meshgrid(array1,array2)生成两个同行同列的多维数组
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
# np.ravel将多维数组降成一维
# np.c_将两个一维数组相同的index值,拼接成一个新的二维数组
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Create color maps
cmap_light = ListedColormap(['#AAFFAA', '#FFAAAA', '#AAAAFF']) #给不同区域赋以颜色
cmap_bold = ListedColormap(['#FF0000', '#003300', '#0000FF'])#给不同属性的点赋以颜色
#将预测的结果在平面坐标中画出其类别区域
# shape(二维数组)返回a,b a=行数,b=维数
# reshape(一维数组, a.b)返回一个a行, b维的
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 也画出所有的训练集数据
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
利用matplotlib绘制测试集合预测结果的伪彩图和样本集合散点图,结果如下: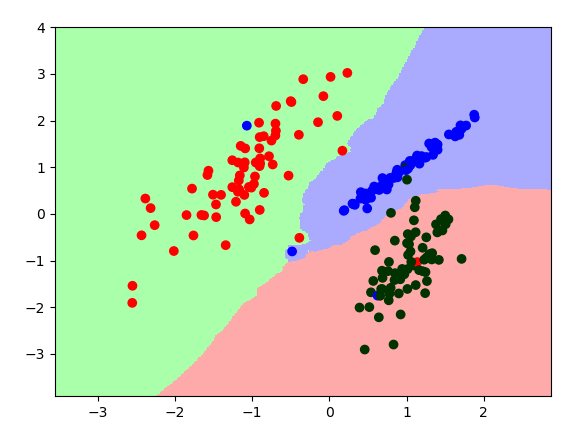
参考
https://baike.baidu.com/item/%E9%82%BB%E8%BF%91%E7%AE%97%E6%B3%95/1151153?fr=aladdin
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html